Lecturer: Dr Philip Blakely
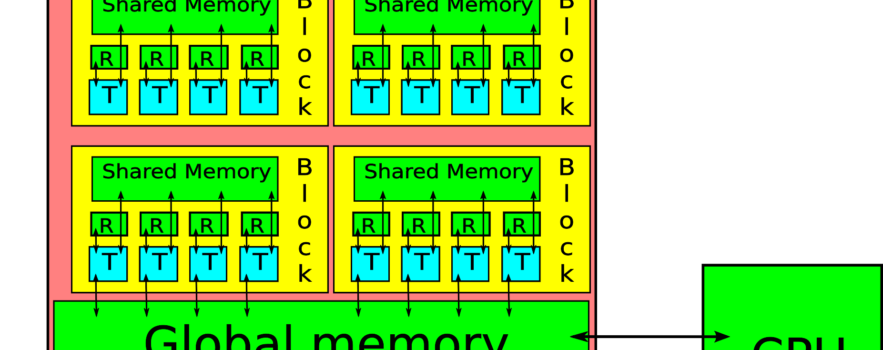
This course will introduce students to the principles of writing scientific software for the latest graphics cards, taking advantage of the highly-parallel nature of the hardware to attain significant speed-ups as compared to traditional CPUs. The course will begin by covering the hardware structure of modern GPUs, and how this relates to the software model. Students will then be introduced to the C-like CUDA programming language which has been developed by NVIDIA, and be shown how to develop efficient algorithms using this language. Students will be introduced to general strategies for optimising code. The main examples used in the course will be related to the numerical solution of PDEs.
Students should leave the course knowing:
- The basics of the CUDA language and hardware and how to compile and run a CUDA code.
- How to best lay out data in memory to achieve good CUDA performance.
- How to use different memory levels in CUDA to improve performance.
- Be aware of some of the more advanced CUDA features that might help performance.
Course structure:
- Introduction to GPU hardware structure and CUDA programming model
- Writing and compiling a simple CUDA code
- Example application: 2D Euler equations
- Optimization strategies and performance tuning
- In-depth coverage of CUDA features
- Combining CUDA with MPI
Practicals:
- Compile and run a CUDA code.
- Transposing a matrix
- Reduction algorithms.
Prerequisites:
- Scientific Computing in C++
Required course for: Any Written Assignment or Research project mentioning GPUs.
Recommended reading:
- https://docs.nvidia.com/cuda/